A collegue in the office was having some problems with uploading documents into a library. The thing was, he was getting errors when he uploads something bigger than 3mb.
So we tried to change web.config of the site, upload size, maxpacketlength etc. They were all looking correct, and the site collection was not loaded completely.
I guess because of the inexperience of using client object model we could not find the answer fast. It took 2 days lol
Nevermind, client object model allows you to upload Binary file directly, you will have NO problems but, Silverlight Api does not have that function, which is:
Microsoft.SharePoint.Client.File.SaveBinaryDirect
So,
If you are having problems with uploading files to the library with Silverlight or WPF Applications, then you should use,
SPWebService contentService = SPWebService.ContentService;
contentService.ClientRequestServiceSettings.MaxReceivedMessageSize = int.MaxValue;
contentService.Update();
26 Temmuz 2011 Salı
WP7 Sharepoint 2010 Lists and Client Object Model
I was developing an Windows Phone 7 application today. As you may know WP7 does not support authentication for NTLM. The only thing you can do (as I know, I am still open for new recommendations) is form based; in which you have to add login information to the request header.
The thing i was doing was using client object model. Actually I could not handle anything, I tried Authentication.asmx and try to get some cookie from there, but I was not able to authenticate myself (because the firm's form based settings were corrupted, and i guess they did not want to create this settings again, and continued with NTLM)
So I added references (Microsoft.Sharepoint.Client and *.Runtime) and created a ClientContext class as:
(ClientContext context = new ClientContext("urlhere"))
Added necessary credentials as:
context.Credentials =
new System.Net.NetworkCredential("username", "pass", "domain");
Fetch my data from a WebService that I created and installed to IIS (You have to create an Empty Asp.Net project, add a web service, build it, and Add an Application to your Site in IIS, show the directory of the ASP.NET project)
Everything was going perfect afterwards, I was able to get data but, sometimes I was seeing this error message:
"The underlying connection was closed: A connection that was expected to be kept alive was closed by the server."
So after a little research I figured it out, this error is caused by WebRequest, which does not close itself after ClientContext.ExecuteQuery() function.
So solution I found was adding this little magical line:
using(ClientContext context = new ClientContext("url"))
{
context.PendingRequest.RequestExecutor.WebRequest.KeepAlive = false
The thing i was doing was using client object model. Actually I could not handle anything, I tried Authentication.asmx and try to get some cookie from there, but I was not able to authenticate myself (because the firm's form based settings were corrupted, and i guess they did not want to create this settings again, and continued with NTLM)
So I added references (Microsoft.Sharepoint.Client and *.Runtime) and created a ClientContext class as:
(ClientContext context = new ClientContext("urlhere"))
Added necessary credentials as:
context.Credentials =
new System.Net.NetworkCredential("username", "pass", "domain");
Fetch my data from a WebService that I created and installed to IIS (You have to create an Empty Asp.Net project, add a web service, build it, and Add an Application to your Site in IIS, show the directory of the ASP.NET project)
Everything was going perfect afterwards, I was able to get data but, sometimes I was seeing this error message:
"The underlying connection was closed: A connection that was expected to be kept alive was closed by the server."
So after a little research I figured it out, this error is caused by WebRequest, which does not close itself after ClientContext.ExecuteQuery() function.
So solution I found was adding this little magical line:
using(ClientContext context = new ClientContext("url"))
{
context.PendingRequest.RequestExecutor.WebRequest.KeepAlive = false
30 Ocak 2011 Pazar
8-Puzzle with A* (A Star) C#
Rather than Depth-First, Breadth-First is complete, which means it will find a solution if it exist. But the solution may be so long and we might need to decide which node to expand, which we don't;

Assume that we are searching for a node with state 4, with regular BFS, (assuming 2 is the node that will be branching to) we need to create 7 nodes to find the node 4.
Function calculates h(x) can be written as;
 In this tree, numbers inside trees represent g(x), path cost. It is zero in root node, because g(x) is relative to root node, and it is increasing in every level of nodes. So, why do we use g(x)? We may find the same node which can generate same child nodes over and over, in different places in the tree. In this situations, to keep solution short, we choose the node with the lower path cost (that is closer to root node) than other which also has same state but more path cost, bottom in the tree. In this way we can reach to the goal state faster and shorten solution sequences.
In this tree, numbers inside trees represent g(x), path cost. It is zero in root node, because g(x) is relative to root node, and it is increasing in every level of nodes. So, why do we use g(x)? We may find the same node which can generate same child nodes over and over, in different places in the tree. In this situations, to keep solution short, we choose the node with the lower path cost (that is closer to root node) than other which also has same state but more path cost, bottom in the tree. In this way we can reach to the goal state faster and shorten solution sequences.
I am going to use the same template that I have used in BFS algorithm I published. The change is going to be in Solve function of course, and in Node object we have a new attribute which is PathCost value. We also need to write set and get functions for PathCost.
For Frontier and Solution, we will use PriorityQueue to make the list faster. It is going to sort the queue after adding new item to the list automatically.
You can find PriorityQueue article at here.
We are going to create another class inherited from this PriorityQueue, that shows different behaviors for Frontier and Solution in AStar.
And of course, our main class AStar.cs will have the following;
Here is the code for Solve function. It is typically same with BFS example.

If we would use BFS, we would create thousands of nodes the find the solution. A Star shows intelligence and is able make choice while searching in the tree.
Here are the code files:
AStar.cs
AStarQueue.cs
Node.cs
PriorityQueue.cs
QueueItem.cs
You will run the code as;

But if our algorithm can see that, branching to node 3 at the first point, is better than branching to 2, because if we branch to 2, we will need to create two extra nodes, which means performance loss.
But how is an BFS algorithm can decide which node to branch?
If an algorithm is able to decide to perform an action than performing another action, it uses a heuristic function.
Heuristic function is shown as h(x). In A* algorithm, use f(x) which equals to g(x) + h(x); which takes advantage of two different methods.
So, what can be h(x) for n-puzzle?
We can use Manhattan Distance to determine h(x) for 8-Puzzle. Manhattan Distance is the measurement of distance between a state and goal state. It is 0 when two states are the same, and it is higher when there are more difference between states.
Let's give an example;
{0,1,2,3,4,5,6,7,8} is goal state, {1,2,0,3,4,5,6,7,8} and {1,0,2,3,5,4,6,8,7} are states we generated. We want to reach to goal state after branching one of these nodes. So we calculate Manhattan Distance;
- h({1,2,0,3,4,5,6,7,8}) = 1+1+1+0+0+0+0+0+0 = 3 because there are only 3 piles which are in wrong space.
- h({1,0,2,3,5,4,6,8,7}) = 1+1+1+1 = 4 because there are 4 tiles in wrong spaces.
We branch to the node with low h(x), which is {1,2,0,3,4,5,6,7,8}.
That's how we make decision.
public int GetHValue(int[] State)
{
int hval = 0;
for (int x = 0; x < 9; x++)
{
if (GoalState[x] != State[x])
hval++;
}
return hval;
}
{
int hval = 0;
for (int x = 0; x < 9; x++)
{
if (GoalState[x] != State[x])
hval++;
}
return hval;
}
And we also have g(x) to consider. g(x) refers to path cost. When you go below in the tree, path cost increases as it decrease when you go back to the root node.
 In this tree, numbers inside trees represent g(x), path cost. It is zero in root node, because g(x) is relative to root node, and it is increasing in every level of nodes. So, why do we use g(x)? We may find the same node which can generate same child nodes over and over, in different places in the tree. In this situations, to keep solution short, we choose the node with the lower path cost (that is closer to root node) than other which also has same state but more path cost, bottom in the tree. In this way we can reach to the goal state faster and shorten solution sequences.
In this tree, numbers inside trees represent g(x), path cost. It is zero in root node, because g(x) is relative to root node, and it is increasing in every level of nodes. So, why do we use g(x)? We may find the same node which can generate same child nodes over and over, in different places in the tree. In this situations, to keep solution short, we choose the node with the lower path cost (that is closer to root node) than other which also has same state but more path cost, bottom in the tree. In this way we can reach to the goal state faster and shorten solution sequences.So; how does A* algorithm take the advantage of both g(x) and h(x)?
If it would only use h(x), it would be categorized as Greedy-Best First algorithm.
Uniform-Cost Search only uses g(x).
A* Searching algorithm follows the following ways to reach to the goal state;
Expands the node which has the lowest f(x) in the Frontier, and then adds it to Solution
- It creates an open list which called as Frontier and closed list which we call as Solution.
- In begins to loop
If a generated child node is in Solution, it is ignored
If it is not in the Frontier, calculates f(x), h(x) and g(x) for nodes and en-queues into frontier
If the node is in the Frontier already; compares the node in the Frontier with new node, and the node in the Frontier is replaced if it's g(x) is higher than new successor's g(x). If it is not, the node is en-queued to the Frontier.
- It ends the loop when the node is the goal state, or when the open list is empty.
I am going to use the same template that I have used in BFS algorithm I published. The change is going to be in Solve function of course, and in Node object we have a new attribute which is PathCost value. We also need to write set and get functions for PathCost.
For Frontier and Solution, we will use PriorityQueue to make the list faster. It is going to sort the queue after adding new item to the list automatically.
You can find PriorityQueue article at here.
We are going to create another class inherited from this PriorityQueue, that shows different behaviors for Frontier and Solution in AStar.
Only functionality change is in IsRepetitionExist function. Which denies the input and stops the function when it is Solution queue, and compare states and their heuristic values when it is Frontier. Here is the code:
- class AStarQueue : PQueue.PriorityQueue<Node>
- {
- int QueueType;
- public AStarQueue(bool AllowRepeat, int QueueType)
- {}
- public override bool IsRepetitionExist(int Key, Node obj)
- {}
- public bool CompareStates(int[] s1, int[] s2)
- {}
- }
- public override bool IsRepetitionExist(int Key, Node obj)
- {
- if (QueueType == 1) //frontier
- {
- LinkedListNode<PQueue.QueueItem<Node>> current = Items.First;
- //Checks other nodes in the frontier
- while (current != null)
- {
- if (CompareStates(current.Value.GetObj().GetState(), obj.GetState()))
- {
- //Compares Path Cost of two nodes
- if (current.Value.GetObj().GetPathCost() > obj.GetPathCost())
- {
- //Replaced the old one if it's deeper than new one.
- Replace(current, new PQueue.QueueItem<Node>(obj.GetHValue() +
- obj.GetPathCost(), obj));
- break;
- }
- }
- current = current.Next;
- }
- return false;
- }
- else
- {
- LinkedListNode<PQueue.QueueItem<Node>> current = Items.First;
- while (current != null && current.Value.GetKey() <= obj.GetHValue())
- {
- if (CompareStates(current.Value.GetObj().GetState(), obj.GetState()))
- return true;
- current = current.Next;
- }
- return false;
- }
- }
And of course, our main class AStar.cs will have the following;
- class AStar
- {
- int[] GoalState = { 0, 1, 2, 3, 4, 5, 6, 7, 8 };
- enum QueueTypeEnum { Frontier = 1, Solution = 2 };
- private AStarQueue Solution;
- private AStarQueue Frontier;
- private Node RootNode;
- public AStar(int[] StartState)
- {
- }
- public void Solve()
- {
- }
- public IEnumerable<Node> GenerateSuccessor(Node ParentNode)
- {
- }
- public bool IsGoalState(int[] State)
- {
- }
- public void WriteSolution()
- {
- }
- public int GetHValue(int[] State)
- {
- }
- public bool CompareStates(int[] s1, int[] s2)
- {
- }
- }
{kind=link}
Here, we are going to focus on Solve function. You can find other functions in my BFS example on this blog.
I've stated that, A* follows following steps;
Expands the node which has the lowest f(x) in the Frontier, and then adds it to Solution
- It creates an open list which called as Frontier and closed list which we call as Solution.
- In begins to loop
If a generated child node is in Solution, it is ignored
If it is not in the Frontier, calculates f(x), h(x) and g(x) for nodes and en-queues into frontier
If the node is in the Frontier already; compares the node in the Frontier with new node, and the node in the Frontier is replaced if it's g(x) is higher than new successor's g(x). If it is not, the node is en-queued to the Frontier.
- It ends the loop when the node is the goal state, or when the open list is empty.
Here is the code for Solve function. It is typically same with BFS example.
When we run it;* This source code was highlighted with Source Code Highlighter.
- public void Solve()
- {
- Node ActiveNode = RootNode;
- bool IsSolved = false;
- while (!IsGoalState(ActiveNode.GetState()) )
- {
- Solution.Enqueue(ActiveNode.GetHValue(),ActiveNode);
- foreach (Node successor in GenerateSuccessor(ActiveNode))
- {
- if (!Solution.IsRepetitionExist(successor.GetHValue() + successor.GetPathCost(), successor))
- {
- Frontier.Enqueue(successor.GetHValue() + successor.GetPathCost(), successor);
- }
- }
- if (IsSolved)
- break;
- ActiveNode = Frontier.Dequeue();
- }
- WriteSolution();
- }
If we would use BFS, we would create thousands of nodes the find the solution. A Star shows intelligence and is able make choice while searching in the tree.
Here are the code files:
AStar.cs
AStarQueue.cs
Node.cs
PriorityQueue.cs
QueueItem.cs
You will run the code as;
* This source code was highlighted with Source Code Highlighter.
- class Program
- {
- static void Main(string[] args)
- {
- int[] ex = { 3,2,4,6,0,1,7,8,5};
- AStar _AStarEx = new AStar(ex);
- _AStarEx.Solve();
- }
- }
28 Ocak 2011 Cuma
Priority Queue in C#
Sometimes we may want more than a queue. A queue which has sorting capability.
You may find some familiar built-in classes in .Net framework, like SortedList, but when you only need to take the item with lowest (or highest; depends on the needs and design) priority, SortedList will be a little bit slow, because you will need to sort it after adding new items to the list, everytime.
In addition, if SortedList has more than one items whose Priorities, or keys, are the same, it will throw an exception. So it requires keys to be unique. But in real life examples, you may have some tasks with same priorities, and you may add 'em to your tasklist.
To make it easier to explain; this image represents the behavior the queue we need;
 As you can see, dequeue just returns Head of the list, it was a easy function to write just like Count function which returns list size.
As you can see, dequeue just returns Head of the list, it was a easy function to write just like Count function which returns list size.
Here is classes that I''ve created:

PriorityQueue is the main class, and has a linked list called as Items, which is has linked list nodes that consist QueueItem class.
QueueItem class consists key, which assures priority manners, and obj which is any object that you wanna add into the Queue.
In PriorityQueue class, more important functions are Dequeue and Enqueue for sure. Dequeue is simple and handled by these lines of codes:
public T Dequeue()
{
if (Items.Count == 0)
return default(T);
else
{
T obj = Items.First.Value.GetObj();
Items.RemoveFirst();
return obj;
}
}
This codes only returns the head of the linked list if it is not empty. Returns default value that represent null if it is empty.
Other function; Enqueue, adds new object with it's key to the list. Here is the code:
public void Enqueue(int key, T obj)
{
LinkedListNode<QueueItem<T>> node = new LinkedListNode<QueueItem<T>>(new QueueItem<T>(key, obj));
if (Items.Count == 0)
{
Items.AddFirst(node);
}
else
{
LinkedListNode<QueueItem<T>> current = Items.First;
while(current != null)
{
if (node.Value.GetKey() <= current.Value.GetKey())
{
Items.AddBefore(current, node);
break;
}
current = current.Next;
}
if (current == null)
Items.AddLast(node);
}
}
///UPDATE
In the old version, it was not possible to prevent repetitions in the list. With some changes it is possible to create a flag that allows or prevents repetitions in the list.
First we add AllowRepeat boolean attribute to the class;
private bool AllowRepeat;
And we change the constructor for the class;
public PriorityQueue(bool RepeatMode)
{
Items = new LinkedList<QueueItem<T>>;
AllowRepeat = RepeatMode;
}
Only time we need to check for repetitions is when we Enqueue data. So we look at Enqueue function and we add this;
if (!AllowRepeat)
{
if (IsRepetitionExist(key, obj))
{
return;
}
}
If AllowRepeat flag is called, it checks IsRepetitionExist function with sending key and obj to it, and checks if the key already exist in the list. It's a virtual function, we might need to change creteria of duplication in the future.
public virtual bool IsRepetitionExist(int Key, T obj)
{
if (Items.Count == 0)
return false;
LinkedListNode<QueueItem <T>> current = Items.First;
int Repetition = 0;
while (current != null || (current != null && current.Value.GetKey() > Key))
{
if (current.Value.GetKey() == Key)
Repetition++;
current = current.Next;
}
if (Repetition < 2)
return false;
else
return true;
}
//END OF UPDATE
First it checks if the list empty; if it is, it is also easy to add to the list by Items.AddFirst(node); command.
If it is not, it checks for every node in the list and it tries to find a node which has higher key (or priority) value than it has. If it finds one, linked list adds new node as previous one of older one, which easily sorts without using other functions.
You can add any objects to the Queue, but Key value must be integer.
Here are the files, ready to use. Only thing you need is to take instance of PriorityQueue class, as easy as;
PriorityQueue<Node> Frontier = new PriorityQueue<Node>();
PriorityQueue.cs
QueueItem.cs
Bon Appetit! :)
You may find some familiar built-in classes in .Net framework, like SortedList, but when you only need to take the item with lowest (or highest; depends on the needs and design) priority, SortedList will be a little bit slow, because you will need to sort it after adding new items to the list, everytime.
In addition, if SortedList has more than one items whose Priorities, or keys, are the same, it will throw an exception. So it requires keys to be unique. But in real life examples, you may have some tasks with same priorities, and you may add 'em to your tasklist.
To make it easier to explain; this image represents the behavior the queue we need;

Here is classes that I''ve created:

PriorityQueue is the main class, and has a linked list called as Items, which is has linked list nodes that consist QueueItem class.
QueueItem class consists key, which assures priority manners, and obj which is any object that you wanna add into the Queue.
In PriorityQueue class, more important functions are Dequeue and Enqueue for sure. Dequeue is simple and handled by these lines of codes:
public T Dequeue()
{
if (Items.Count == 0)
return default(T);
else
{
T obj = Items.First.Value.GetObj();
Items.RemoveFirst();
return obj;
}
}
This codes only returns the head of the linked list if it is not empty. Returns default value that represent null if it is empty.
Other function; Enqueue, adds new object with it's key to the list. Here is the code:
public void Enqueue(int key, T obj)
{
LinkedListNode<QueueItem<T>> node = new LinkedListNode<QueueItem<T>>(new QueueItem<T>(key, obj));
if (Items.Count == 0)
{
Items.AddFirst(node);
}
else
{
LinkedListNode<QueueItem<T>> current = Items.First;
while(current != null)
{
if (node.Value.GetKey() <= current.Value.GetKey())
{
Items.AddBefore(current, node);
break;
}
current = current.Next;
}
if (current == null)
Items.AddLast(node);
}
}
///UPDATE
In the old version, it was not possible to prevent repetitions in the list. With some changes it is possible to create a flag that allows or prevents repetitions in the list.
First we add AllowRepeat boolean attribute to the class;
private bool AllowRepeat;
And we change the constructor for the class;
public PriorityQueue(bool RepeatMode)
{
Items = new LinkedList<QueueItem<T>>;
AllowRepeat = RepeatMode;
}
Only time we need to check for repetitions is when we Enqueue data. So we look at Enqueue function and we add this;
if (!AllowRepeat)
{
if (IsRepetitionExist(key, obj))
{
return;
}
}
If AllowRepeat flag is called, it checks IsRepetitionExist function with sending key and obj to it, and checks if the key already exist in the list. It's a virtual function, we might need to change creteria of duplication in the future.
public virtual bool IsRepetitionExist(int Key, T obj)
{
if (Items.Count == 0)
return false;
LinkedListNode<QueueItem <T>> current = Items.First;
int Repetition = 0;
while (current != null || (current != null && current.Value.GetKey() > Key))
{
if (current.Value.GetKey() == Key)
Repetition++;
current = current.Next;
}
if (Repetition < 2)
return false;
else
return true;
}
//END OF UPDATE
First it checks if the list empty; if it is, it is also easy to add to the list by Items.AddFirst(node); command.
If it is not, it checks for every node in the list and it tries to find a node which has higher key (or priority) value than it has. If it finds one, linked list adds new node as previous one of older one, which easily sorts without using other functions.
You can add any objects to the Queue, but Key value must be integer.
Here are the files, ready to use. Only thing you need is to take instance of PriorityQueue class, as easy as;
PriorityQueue<Node> Frontier = new PriorityQueue<Node>();
PriorityQueue.cs
QueueItem.cs
Bon Appetit! :)
12 Ocak 2011 Çarşamba
8 Puzzle with Depth First Search and C#
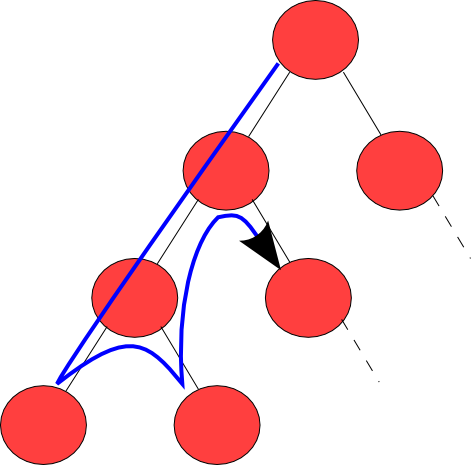
So let's start!
You will need same functions mentioned at Breadth-First example; you have to change Frontier and it's functions for Stack, Node.cs will remain same, you can reach it with this address: Node.cs.
Your main will initialize DFS for this example;
static void Main(string[] args)
{
int[] ex = { 1, 2, 3, 0, 4, 5, 6, 7, 8 };
DFS_dfs = new DFS(ex);
_dfs.Solve();
}
DFS.cs file will have;
private Stack<Node> Frontier instead of private Queue<Node> Frontier.
It will contain;
class DFS
{
int[] GoalState = { 0, 1, 2, 3, 4, 5, 6, 7, 8 };
private Stack<Node> Frontier;
private HashSet<Node> Solution;
private Node RootNode;
public DFS(int[] StartState)
{}
public void Solve()
{}
public IEnumerable<Node> GenerateSuccessor(Node ParentNode)
{}
public bool IsGoalState(int[] State)
{}
public void WriteSolution()
{}
}
The only change is in Solve function; to add an item to a Stack you use Push command instead of Enqueue which used in Queues, just like Pop command for Dequeue.
Solve function will be;
- public void Solve()
- {
- Node ActiveNode = RootNode;
- bool IsSolved = false;
- while (!IsGoalState(ActiveNode.GetState()))
- {
- Solution.Add(ActiveNode);
- foreach(Node successor in GenerateSuccessor(ActiveNode))
- {
- Frontier.Push(successor);
- if (IsGoalState(successor.GetState()))
- {
- IsSolved = true;
- Solution.Add(successor);
- break;
- }
- }
- if (IsSolved)
- break;
- ActiveNode = Frontier.Pop();
- }
- WriteSolution();
- }
It is not fast as BFS, and generally you don't get much result in 8-Puzzle problems with Depth First Search, because it just create successors over a branch, if that branch doesn't bring us to the solution, we might never find it. So, DFS is not complete.
Source Files:
DFS.cs
Node.cs
Program.cs
8 Puzzle with Breadth First Search and C#
 8 puzzle is a puzzle has 3x3 squares. It is a sliding puzzle, so to solve it, you have to move the empty square to end or beginning, and align other squares in order (order or alignment may differ among different type of puzzles)
8 puzzle is a puzzle has 3x3 squares. It is a sliding puzzle, so to solve it, you have to move the empty square to end or beginning, and align other squares in order (order or alignment may differ among different type of puzzles)There can be a different solution paths of a 8 Puzzle, but the goal state is determined and always the same.
Today we are going to use C# to write an agent that solves (or try to solve) any unsolved 8 puzzle examples given. In my examples, 8 Puzzle has a goal state which is {1,2,3,4,5,6,7,8,0}. 0 represents the empty square, and since it is 9th element in the array, it would be on the 3rd row and 3rd column on the given example image.
Let's start!
Create a C# Console Application and name it as 8PuzzleBFS.
We create 2 classes: BFS.cs and Node.cs. We will use Program.cs which consists Main procedure as main class that controls the software and algorithm.
- Start with Node.cs. It is going to have the State the Node in. ID of the generated Node which starts with 0 if there is no previous one, and get/set functions. Also, the Move which applied to parent state the generate the successor, and ParentID determines parent.
- In BFS.cs, we will need a function that generates new nodes, a function that checks if the node is in goal state, and a Queue, list for Solution,
class Node
{
static int _IdCnt = 0;
private int[] State;
private int Id;
private int ParentId;
private char Move;
public Node(int[] State,int ParentId, char Move)
{}
public void SetState(int[] State)
{}
public int[] GetState()
{}
public int GetId()
{}
public int GetParentId()
{}
public char GetMove()
{}
}
and BFS.cs has;
class BFS
{
int[] GoalState = { 0, 1, 2, 3, 4, 5, 6, 7, 8 };
private Queue<Node> Frontier;
private HashSet<Node> Solution;
private Node RootNode;
public BFS(int[] StartState)
{}
public void Solve()
{}
public IEnumerable<Node> GenerateSuccessor(Node ParentNode)
{}
public bool IsGoalState(int[] State)
{}
public void WriteSolution()
{}
}
To run the software; we create an instance of BFS, and give an example, "s";
static void Main(string[] args)
{
int[] s = { 1, 2, 3, 0, 4, 5, 6, 7, 8 };
BFS _bfs = new BFS(s);
_bfs.Solve();
}
Here is the screenshot of running software:

Source Files:
BFS.cs
Node.cs
Program.cs
2 Ocak 2011 Pazar
Depth-First Search
Daha onceki entry'de, Tree'nin bir level'i icerisindeki tum nodelar uzerinde arama yapmadan, bir sonraki level'a gecmeyen ve complete bir arama yontemi olan Breadth-First searchden soz etmistim.
Depth-First Search ise yine Breadth-First gibi bir arama algoritmasidir. Ondan farki ise complete olmamasidir ve tek bir branch uzerinde, cozumu buluncaya (yada bulamayacagina kanaat getirene) kadar aramaya, node'un successorleri yaratmaya devam eder.
Depth-First Search'in Breadth-First'den diger farki ise Queue yerine Stack kullanmasidir. Stack bir LIFO listesidir. LIFO, Last in first out anlamina gelmektedir. Yani Stack'a push komutuyla birkac veri eklediginizde, pop komutu kullanarak stack'dan bir oge almak isterseniz, listeden alacaginiz veri, en son eklediginiz veridir. Queue'nin tam tersi yani.

Yukaridaki tree ornegine bakicak olursak, Breadth-First kullansaydik, root node olan 4 den 1 e ulasmak icin izleyecegimiz yolu belirlerken, Solution listemizde bulunan nodelar sirasiyla 4,2,6,1 olucakti. Depth-First kullanirsak solution listemiz ise 4, 2, 1'i icerir.
Depth-First Search, tree'nin guncel dalinin en sonundaki node, deaf node olana kadar, baska bir branch'a gecmez, ayni sekilde derin levellara dogru devam eder.
Yukaridaki treede Depth-First kullanmamiz isimize yaradi, Breadth-First'ten daha verimli bir sekilde cozumu bulabildi. Fakat tamamen sans eseri; eger en soldaki branchda deaf node olmasaydi ve biz 7 yi arasaydik, en soldaki branch icerisinde sonsuza kadar derinlere inerdi (deaf node olmasaydi derken sonsuz level oldugunu farzediyorum) ve cozumu bulamazdi. Dolayisiyla complete degil, ama bazi durumlarda Breadth-First'den daha iyi perfonmans saglayabilir.
Yukaridaki Tree ornegine bakacak olursak, yani 4 node'undan 1 node'una ulasmak istersek, Stack ve Solution listesi adim adim su verilere sahip olacak.
Current Node: 4
Frontier Stack: Empty
Solution List: Empty
Current Node: 4
Frontier Stack: 2 6
Solution List: 4
Current Node: 2
Frontier Stack: 6
Solution List: 4
Current Node: 2
Frontier Stack: 1 3 6
Solution List: 4 2
Current Node: 1
Frontier Stack: 3 6
Solution List: 4 2
Current Node: 1
Frontier Stack: 3 6
Solution List: 4 2 1 //Cozum bulundu
Yazarak adim adim anlatmak gerekirse,
Depth-First Search ise yine Breadth-First gibi bir arama algoritmasidir. Ondan farki ise complete olmamasidir ve tek bir branch uzerinde, cozumu buluncaya (yada bulamayacagina kanaat getirene) kadar aramaya, node'un successorleri yaratmaya devam eder.
Depth-First Search'in Breadth-First'den diger farki ise Queue yerine Stack kullanmasidir. Stack bir LIFO listesidir. LIFO, Last in first out anlamina gelmektedir. Yani Stack'a push komutuyla birkac veri eklediginizde, pop komutu kullanarak stack'dan bir oge almak isterseniz, listeden alacaginiz veri, en son eklediginiz veridir. Queue'nin tam tersi yani.

Yukaridaki tree ornegine bakicak olursak, Breadth-First kullansaydik, root node olan 4 den 1 e ulasmak icin izleyecegimiz yolu belirlerken, Solution listemizde bulunan nodelar sirasiyla 4,2,6,1 olucakti. Depth-First kullanirsak solution listemiz ise 4, 2, 1'i icerir.
Depth-First Search, tree'nin guncel dalinin en sonundaki node, deaf node olana kadar, baska bir branch'a gecmez, ayni sekilde derin levellara dogru devam eder.
Yukaridaki treede Depth-First kullanmamiz isimize yaradi, Breadth-First'ten daha verimli bir sekilde cozumu bulabildi. Fakat tamamen sans eseri; eger en soldaki branchda deaf node olmasaydi ve biz 7 yi arasaydik, en soldaki branch icerisinde sonsuza kadar derinlere inerdi (deaf node olmasaydi derken sonsuz level oldugunu farzediyorum) ve cozumu bulamazdi. Dolayisiyla complete degil, ama bazi durumlarda Breadth-First'den daha iyi perfonmans saglayabilir.
Yukaridaki Tree ornegine bakacak olursak, yani 4 node'undan 1 node'una ulasmak istersek, Stack ve Solution listesi adim adim su verilere sahip olacak.
Current Node: 4
Frontier Stack: Empty
Solution List: Empty
Current Node: 4
Frontier Stack: 2 6
Solution List: 4
Current Node: 2
Frontier Stack: 6
Solution List: 4
Current Node: 2
Frontier Stack: 1 3 6
Solution List: 4 2
Current Node: 1
Frontier Stack: 3 6
Solution List: 4 2
Current Node: 1
Frontier Stack: 3 6
Solution List: 4 2 1 //Cozum bulundu
Yazarak adim adim anlatmak gerekirse,
- Current Node 4
- 4 un child nodelari 2 ve 6 frontier'e eklenir ve 4 solution list'e eklenir
- frontierdeki ilk child olan 2 nin child nodelari frontiere eklenir; 1 ve 3. Ve 2 solution a eklenir.
- frontierin su anki durumu 1 3 ve 6 iken solutionda 4, 2 bulunur.
- frontierdan pop komutuyla yine bir child alinir, 1 current node olur.
- current node aranilan node oldugundan solution'a eklenir.
- solution da 4, 2, 1 bulunurkan frontier ve current node temizlenir.
Breadth-First Search

Gordugumuz bir Tree. 1 Root node, kendisi 2, 3 ve 4 u uretmis, ayni sekilde 2, 5 ve 6 yi vs..
Ornek problem vermek gerekirse, agentimiz Node 1 deki state'den Node 10'a varmaya calisiyor.
Searching algorithmlerden soz ederken, 2 cesit liste turunden bahsederiz. Cozumun adim adim saklandigi bir liste, Cozum yada Solution Listesi, ve bir onceki Node'un childlarini iceren Frontier Listesi.
Ilk olarak arama su sekilde gerceklesir. Current Node, Solution listesine eklenir. Current Node'un childlari Frontier listesine eklenir. Bu andan itibaren, Frontier listesinin ilk elemani secilir, Childlari Frontier listesine eklenir, kendisi Frontier listesinden silinip, Solution listesine eklenir. Secilen frontier elemani, aradigimiz Node yada State (Durum) olana kadar devam eder yani frontier listesinin ilk elemani dequeue edilir, onun cocuk nodelari frontier'e eklenir ve dequeue edilen node solution'a eklenir.
Bahsettigimiz iki liste, Frontier ve Solution listesinin veri tipleri onemlidir. Breadth First'de Frontier bir FIFO listesi yani Queue dir. Kodlanan programlama diline gore Solution'a herhangi bir hizli veri turu atayabilirsiniz. HashSet gibi. Fakat Solution da Queue olabilir, bir sakincasi bulunmamaktadir.
Queue veya FIFO hakkinda bilgi vermek gerekirse:
FIFO, first in first out anlamina gelmektedir. Ilk giren son cikar, turkce karsiligiyla.
Queue'ye bir veri girisi yaparken, Enqueue yapmis olursunuz. Queue'nin en eski elemanini Queue'den koparip bir degiskene atamak icin Dequeue fonksiyonunu kullanabilirsiniz.
Asagidaki ornekte Queue'ye A node'u ve ardindan B node'u sokuluyor. A Queue'nin en eski elemani oldugundan, cagirilan bir Dequeue fonksiyonu sonucunda, Queue'den ilk olarak silinecek Node ta kendisi.

Konuya geri donecek olursak Breadth First complete bir arama algoritmasidir. Tum olasiliklari dener ve bir cozum varsa, kesinlikle bunu bulur. Fakat her node'u teker teker denediginden perfonmans konusunda zayiftir (yinede baska birkac arama algoritmasindan daha hizli)
Frontier'e child nodelari eklerken, her zaman soldan saga bir yol izler. Ve bir leveldaki tum nodelari denemeden (yada frontier'e eklemeden) daha derin bir level'e inmez.
Yukaridaki verileri goz onune aldigimizda, 1 den 10 a varmak istersek, Breadth-First search asagidaki asamalardan gecerek bizi sonuca ulastirir.
Current Node: 1
Solution List: Bos
Frontier Queue: Bos
Current Node: 1
Solution List:
Frontier Queue: 2 3 4
Current Node: 2
Solution List: 1
Frontier Queue: 3 4
Current Node: 2
Solution List: 1 2
Frontier Queue: 3 4 5 6
Current Node: 3
Solution List: 1 2
Frontier Queue: 4 5 6
Current Node: 3
Solution List: 1 2 3
Frontier Queue: 4 5 6
* (3 child'a sahip degil)
Current Node: 4
Solution List: 1 2 3
Frontier Queue: 5 6
Current Node: 4
Solution List: 1 2 3 4
Frontier Queue: 5 6 7 8
Current Node: 5
Solution List: 1 2 3 4
Frontier Queue: 6 7 8
Current Node: 5
Solution List: 1 2 3 4 5
Frontier Queue: 6 7 8 9 10
Current Node: 6
Solution List: 1 2 3 4 5
Frontier Queue: 7 8 9 10
Current Node: 6
Solution List: 1 2 3 4 5 6
Frontier Queue: 7 8 9 10
Current Node: 7
Solution List: 1 2 3 4 5 6
Frontier Queue: 8 9 10
Current Node: 7
Solution List: 1 2 3 4 5 6 7
Frontier Queue: 8 9 10 11 12
Current Node: 8
Solution List: 1 2 3 4 5 6 7
Frontier Queue: 9 10 11 12
Current Node: 8
Solution List: 1 2 3 4 5 6 7 8
Frontier Queue: 9 10 11 12
Current Node: 9
Solution List: 1 2 3 4 5 6 7 8
Frontier Queue: 10 11 12
Current Node: 9
Solution List: 1 2 3 4 5 6 7 8 9
Frontier Queue: 10 11 12
//cozum bulundu
Current Node: 10
Solution List: 1 2 3 4 5 6 7 8 10
Frontier Queue: temizlendi.
Gordugumuz gibi son durumda Current Node, 10. Aradigimiz node 10 oldugundan algoritma bize solutionu dondurecek.
Solution List 1 2 3 4 5 6 7 8 10 u iceriyor. Her child node'un parent node'unun idsini barindirdigini varsayarsak (ki bir dizi halinde sonucu gostermek icin bu destegi saglamaliyiz), 10 dan baslayarak geriye donmeliyiz.
Yazacigimiz ufak bir fonksiyon su sart ifadeleri icerisinde cozumu dondurmeli.
v_id = 10'un idsi.
Dongu
Eger v_id null ise
Donguden cik
v_node = solution icerisinde id'si v_id degiskenine esit olan node
v_id = v_node'un id si
Dongu Bitis
Breadth First Search, bir cozum varsa onu mutlaka dondurur, Queue kullanir, ve Tree'yi level, level tarar, ve bir level icerisindeki nodelar aranilan durumu icermiyorsa, tree'nin bir level asagisina inerek en soldaki node'u kontrol eder. Eger sonuc o degilse, node'un cocuklarini frontier'e ekler.

Arama Algoritmalari
Arama Algoritmalari belli bir veri koleksiyonundaki, (Tree) veriler icerisinde, aranilan veriyi bulmamizi saglayan, ve bunu bir yontem kullanarak yapan algoritmalara verilen addir. Arama algoritmasi, ana node'dan aranilan node'a ulasabilecegimiz bir cozum yolu geri dondurebilecegi gibi, cozumun adim-adim yazilmasini gerektirmeyen durumlarda, cozumun kendisini kullaniciya dondurebilir.

Yukarida gordugumuz bir Tree. 103 Tree'nin baslangic noktasi. 103 Node'unu Root Node olarak adlandiriyoruz, kendisi kok cunku. 103 Node'undan 102 ve 104 e giden cubuklar, 103 node'unun 102 ve 104 node'unun parent'i oldugunu gosteriyor. Ayni sekilde 102 ve 104, 103 un child'i.
Ayni sekilde 102, 101 in parenti iken, 105, 104'un childi.
Ornek Tree'miz 3 Level bir Tree. Level 0 da 103 yer alirken, Level 1 de 102 ve 104, level 2 de 101 ve 105 yer almakta.
Arama algoritmasi, yukaridaki gibi bir tree icerisinde, 103 konumunda olan agentimizin, 101 durumuna nasil gelebilecegini bir cozum serisi ile bize geri dondurebilir.
Ornegin, 103 durumundan, 101 e erismek istiyoruz. Izleyecegimiz en efentif yol:
103->102
102->101 'dir.
Cozum 2 aksiyon icermekle beraber, en basit cozumdur. Bunun disinda farkli bir cozum olan:
103->104
104->105
105->104
104->103
103-> 102
102->101, toplam 6 farkli aksiyon icermekte. Kesinlikle en efektif cozum degil.
Sonuc olarak, 103 den 101 e ulasmak icin icin su anlik elimizden 2 farkli yontem var. Her 2 yontem ayri bir arama algoritmasina ait.
Kisacasi, cozume ulasirken izledigimiz her farkli yontem, farkli bir arama algoritmasi. Arama algoritmasi, Current Node'dan, (yukaridaki resimde 103 oldugunu farzediyorum), 102 node'una veya onun yerine 104 node'una dallanmamiza karar veren, ve o node'dan sonra bir sonraki node'a dallanan, bunu sistematik bir yolla yapan, ve aranilan durumu, ya da cozumu, (Solution State) bulana kadar bu sekilde bir dongu icerisinde devam eden algoritmadir.
Treeler uzerinde kullanilan arama algoritmalarini Informed ve Uninformed Search Algorithms olarak ikiye ayirabiliriz.
Informed Search Algorithms, belli bir Heuristic fonksiyonu kullanarak bir zeka piriltisi gostermektedir. Uninformed Search ise herhangi bir zekasal yonteme dayanmadan, suanki Node'dan bir sonraki Node'a gecer.
Bir sonraki yazida uninformed search algoritmasi olan, Breadth-First Searching den bahsedecegim.
Yukarida gordugumuz bir Tree. 103 Tree'nin baslangic noktasi. 103 Node'unu Root Node olarak adlandiriyoruz, kendisi kok cunku. 103 Node'undan 102 ve 104 e giden cubuklar, 103 node'unun 102 ve 104 node'unun parent'i oldugunu gosteriyor. Ayni sekilde 102 ve 104, 103 un child'i.
Ayni sekilde 102, 101 in parenti iken, 105, 104'un childi.
Ornek Tree'miz 3 Level bir Tree. Level 0 da 103 yer alirken, Level 1 de 102 ve 104, level 2 de 101 ve 105 yer almakta.
Arama algoritmasi, yukaridaki gibi bir tree icerisinde, 103 konumunda olan agentimizin, 101 durumuna nasil gelebilecegini bir cozum serisi ile bize geri dondurebilir.
Ornegin, 103 durumundan, 101 e erismek istiyoruz. Izleyecegimiz en efentif yol:
103->102
102->101 'dir.
Cozum 2 aksiyon icermekle beraber, en basit cozumdur. Bunun disinda farkli bir cozum olan:
103->104
104->105
105->104
104->103
103-> 102
102->101, toplam 6 farkli aksiyon icermekte. Kesinlikle en efektif cozum degil.
Sonuc olarak, 103 den 101 e ulasmak icin icin su anlik elimizden 2 farkli yontem var. Her 2 yontem ayri bir arama algoritmasina ait.
Kisacasi, cozume ulasirken izledigimiz her farkli yontem, farkli bir arama algoritmasi. Arama algoritmasi, Current Node'dan, (yukaridaki resimde 103 oldugunu farzediyorum), 102 node'una veya onun yerine 104 node'una dallanmamiza karar veren, ve o node'dan sonra bir sonraki node'a dallanan, bunu sistematik bir yolla yapan, ve aranilan durumu, ya da cozumu, (Solution State) bulana kadar bu sekilde bir dongu icerisinde devam eden algoritmadir.
Treeler uzerinde kullanilan arama algoritmalarini Informed ve Uninformed Search Algorithms olarak ikiye ayirabiliriz.
Informed Search Algorithms, belli bir Heuristic fonksiyonu kullanarak bir zeka piriltisi gostermektedir. Uninformed Search ise herhangi bir zekasal yonteme dayanmadan, suanki Node'dan bir sonraki Node'a gecer.
Bir sonraki yazida uninformed search algoritmasi olan, Breadth-First Searching den bahsedecegim.
Kaydol:
Yorumlar (Atom)