
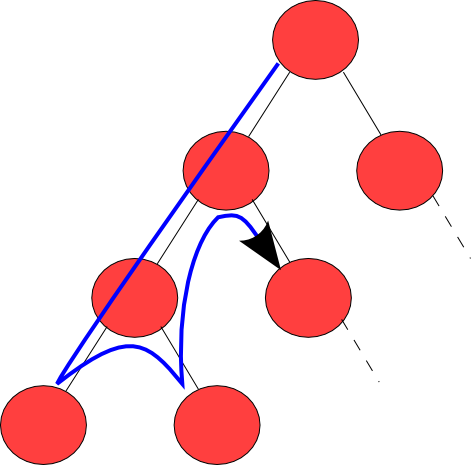
But if our algorithm can see that, branching to node 3 at the first point, is better than branching to 2, because if we branch to 2, we will need to create two extra nodes, which means performance loss.
But how is an BFS algorithm can decide which node to branch?
If an algorithm is able to decide to perform an action than performing another action, it uses a heuristic function.
Heuristic function is shown as h(x). In A* algorithm, use f(x) which equals to g(x) + h(x); which takes advantage of two different methods.
So, what can be h(x) for n-puzzle?
We can use Manhattan Distance to determine h(x) for 8-Puzzle. Manhattan Distance is the measurement of distance between a state and goal state. It is 0 when two states are the same, and it is higher when there are more difference between states.
Let's give an example;
{0,1,2,3,4,5,6,7,8} is goal state, {1,2,0,3,4,5,6,7,8} and {1,0,2,3,5,4,6,8,7} are states we generated. We want to reach to goal state after branching one of these nodes. So we calculate Manhattan Distance;
- h({1,2,0,3,4,5,6,7,8}) = 1+1+1+0+0+0+0+0+0 = 3 because there are only 3 piles which are in wrong space.
- h({1,0,2,3,5,4,6,8,7}) = 1+1+1+1 = 4 because there are 4 tiles in wrong spaces.
We branch to the node with low h(x), which is {1,2,0,3,4,5,6,7,8}.
That's how we make decision.
public int GetHValue(int[] State)
{
int hval = 0;
for (int x = 0; x < 9; x++)
{
if (GoalState[x] != State[x])
hval++;
}
return hval;
}
{
int hval = 0;
for (int x = 0; x < 9; x++)
{
if (GoalState[x] != State[x])
hval++;
}
return hval;
}
And we also have g(x) to consider. g(x) refers to path cost. When you go below in the tree, path cost increases as it decrease when you go back to the root node.
 In this tree, numbers inside trees represent g(x), path cost. It is zero in root node, because g(x) is relative to root node, and it is increasing in every level of nodes. So, why do we use g(x)? We may find the same node which can generate same child nodes over and over, in different places in the tree. In this situations, to keep solution short, we choose the node with the lower path cost (that is closer to root node) than other which also has same state but more path cost, bottom in the tree. In this way we can reach to the goal state faster and shorten solution sequences.
In this tree, numbers inside trees represent g(x), path cost. It is zero in root node, because g(x) is relative to root node, and it is increasing in every level of nodes. So, why do we use g(x)? We may find the same node which can generate same child nodes over and over, in different places in the tree. In this situations, to keep solution short, we choose the node with the lower path cost (that is closer to root node) than other which also has same state but more path cost, bottom in the tree. In this way we can reach to the goal state faster and shorten solution sequences.So; how does A* algorithm take the advantage of both g(x) and h(x)?
If it would only use h(x), it would be categorized as Greedy-Best First algorithm.
Uniform-Cost Search only uses g(x).
A* Searching algorithm follows the following ways to reach to the goal state;
Expands the node which has the lowest f(x) in the Frontier, and then adds it to Solution
- It creates an open list which called as Frontier and closed list which we call as Solution.
- In begins to loop
If a generated child node is in Solution, it is ignored
If it is not in the Frontier, calculates f(x), h(x) and g(x) for nodes and en-queues into frontier
If the node is in the Frontier already; compares the node in the Frontier with new node, and the node in the Frontier is replaced if it's g(x) is higher than new successor's g(x). If it is not, the node is en-queued to the Frontier.
- It ends the loop when the node is the goal state, or when the open list is empty.
I am going to use the same template that I have used in BFS algorithm I published. The change is going to be in Solve function of course, and in Node object we have a new attribute which is PathCost value. We also need to write set and get functions for PathCost.
For Frontier and Solution, we will use PriorityQueue to make the list faster. It is going to sort the queue after adding new item to the list automatically.
You can find PriorityQueue article at here.
We are going to create another class inherited from this PriorityQueue, that shows different behaviors for Frontier and Solution in AStar.
Only functionality change is in IsRepetitionExist function. Which denies the input and stops the function when it is Solution queue, and compare states and their heuristic values when it is Frontier. Here is the code:
- class AStarQueue : PQueue.PriorityQueue<Node>
- {
- int QueueType;
- public AStarQueue(bool AllowRepeat, int QueueType)
- {}
- public override bool IsRepetitionExist(int Key, Node obj)
- {}
- public bool CompareStates(int[] s1, int[] s2)
- {}
- }
- public override bool IsRepetitionExist(int Key, Node obj)
- {
- if (QueueType == 1) //frontier
- {
- LinkedListNode<PQueue.QueueItem<Node>> current = Items.First;
- //Checks other nodes in the frontier
- while (current != null)
- {
- if (CompareStates(current.Value.GetObj().GetState(), obj.GetState()))
- {
- //Compares Path Cost of two nodes
- if (current.Value.GetObj().GetPathCost() > obj.GetPathCost())
- {
- //Replaced the old one if it's deeper than new one.
- Replace(current, new PQueue.QueueItem<Node>(obj.GetHValue() +
- obj.GetPathCost(), obj));
- break;
- }
- }
- current = current.Next;
- }
- return false;
- }
- else
- {
- LinkedListNode<PQueue.QueueItem<Node>> current = Items.First;
- while (current != null && current.Value.GetKey() <= obj.GetHValue())
- {
- if (CompareStates(current.Value.GetObj().GetState(), obj.GetState()))
- return true;
- current = current.Next;
- }
- return false;
- }
- }
And of course, our main class AStar.cs will have the following;
- class AStar
- {
- int[] GoalState = { 0, 1, 2, 3, 4, 5, 6, 7, 8 };
- enum QueueTypeEnum { Frontier = 1, Solution = 2 };
- private AStarQueue Solution;
- private AStarQueue Frontier;
- private Node RootNode;
- public AStar(int[] StartState)
- {
- }
- public void Solve()
- {
- }
- public IEnumerable<Node> GenerateSuccessor(Node ParentNode)
- {
- }
- public bool IsGoalState(int[] State)
- {
- }
- public void WriteSolution()
- {
- }
- public int GetHValue(int[] State)
- {
- }
- public bool CompareStates(int[] s1, int[] s2)
- {
- }
- }
Here, we are going to focus on Solve function. You can find other functions in my BFS example on this blog.
I've stated that, A* follows following steps;
Expands the node which has the lowest f(x) in the Frontier, and then adds it to Solution
- It creates an open list which called as Frontier and closed list which we call as Solution.
- In begins to loop
If a generated child node is in Solution, it is ignored
If it is not in the Frontier, calculates f(x), h(x) and g(x) for nodes and en-queues into frontier
If the node is in the Frontier already; compares the node in the Frontier with new node, and the node in the Frontier is replaced if it's g(x) is higher than new successor's g(x). If it is not, the node is en-queued to the Frontier.
- It ends the loop when the node is the goal state, or when the open list is empty.
Here is the code for Solve function. It is typically same with BFS example.
When we run it;* This source code was highlighted with Source Code Highlighter.
- public void Solve()
- {
- Node ActiveNode = RootNode;
- bool IsSolved = false;
- while (!IsGoalState(ActiveNode.GetState()) )
- {
- Solution.Enqueue(ActiveNode.GetHValue(),ActiveNode);
- foreach (Node successor in GenerateSuccessor(ActiveNode))
- {
- if (!Solution.IsRepetitionExist(successor.GetHValue() + successor.GetPathCost(), successor))
- {
- Frontier.Enqueue(successor.GetHValue() + successor.GetPathCost(), successor);
- }
- }
- if (IsSolved)
- break;
- ActiveNode = Frontier.Dequeue();
- }
- WriteSolution();
- }

If we would use BFS, we would create thousands of nodes the find the solution. A Star shows intelligence and is able make choice while searching in the tree.
Here are the code files:
AStar.cs
AStarQueue.cs
Node.cs
PriorityQueue.cs
QueueItem.cs
You will run the code as;
* This source code was highlighted with Source Code Highlighter.
- class Program
- {
- static void Main(string[] args)
- {
- int[] ex = { 3,2,4,6,0,1,7,8,5};
- AStar _AStarEx = new AStar(ex);
- _AStarEx.Solve();
- }
- }









{kind=link}